Building your Digital Attic
knowledge21 Dec 2020
3 minute read
A digital attic is a collection of the links and content you’ve found on the web. I store mine in a markdown file (source). It’s meant to be easy to move around and share, and I usually update mine every once in a while by pooling from my bookmarks.
This “attic” has two purposes:
- Have a readable, clear organization of all the cool stuff you find online. This allows you to look back on old content easily. The problem with the way most browsers handle bookmarks is that you always have to go through a certain amount of effort to have some sort of flexible, readable and clean organization of your links.
- Be able to share the things you’ve found interesting and also exchange with other people’s attics.
I’ve found some similar implementations of digital attics online, and always found them insightful and useful.
However, this process of indexing and then revisiting these links showed me another problem with the way content persists on the web.
Link rot #
I updated my attic yesterday, and noticed that quite a few links no longer returned anything.
This is link rot, the gradual abandonment of websites / content that leads to a loss of information and public record.
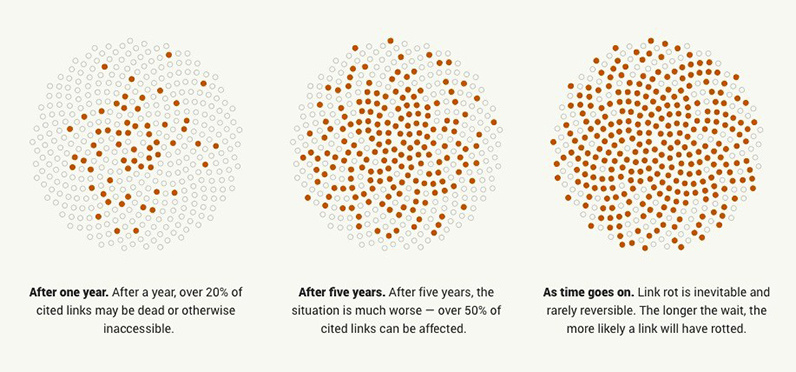
This loss is linked to the financial / time commitment needed to run a website. Jeff Huang’s manifesto “Designed to Last” also describes this problem and potential ways to simplify serving content and make your websites more resilient.
Another approach, proposed by the Internet Archive and its amazing Wayback Machine initiative is to actually store copies of websites as they were in the past.
A similar way I’m trying to work on this problem is Archivy, a knowledge base tool that stores local copies of web-pages in Markdown. One of its core focuses is extensibility and building in ways for users to interact with their knowledge programmatically.
Making things easy #
Organizational tasks like these can sometimes get tedious (especially if you have to check if the links still work), and it can be annoying to waste too much time on updating your attic. This is why in my case I wrote a simple Crystal script that converts the Firefox JSON bookmark export to clean Markdown.
Since there are obviously some links I don’t think are useful to put into my attic, I also added some functionality where you can store a file with links to be ignored.
This process helps me quickly update my attic whenever I feel like it, but more than that, it would make it easy for me to download web-pages automatically, preventing them from degrading with link rot.
I’m thinking about adding a few features to this tool that would work against this problem:
- The code could connect to the Archivy Web API and pass it the page URLs for it to save and mirror them.
- Automatic checking of which links are no longer up.
I recommend finding a way to automate the action of updating your attic if you build one, because it’ll help make the process more fun.
This concept is merely an idea for a manner in which you can index this information, but I’m sure there are many other innovative and creative way to go about this (and I’d love to hear about them!).
If you find any other intriguing attics, please link them! I’m always curious :)
